






引言
随着互联网技术的飞速发展,大数据时代已经到来。在众多大数据处理技术中,实时数据处理技术成为了研究的热点。实时Storm协同过滤算法作为一种高效的实时推荐算法,在电子商务、社交媒体、在线教育等领域得到了广泛应用。本文将详细介绍实时Storm协同过滤算法的原理、实现方法及其在实际应用中的优势。
实时Storm协同过滤算法的原理
实时Storm协同过滤算法是一种基于实时数据流的推荐算法,它通过分析用户的历史行为数据,实时预测用户可能感兴趣的项目。该算法主要分为以下几个步骤:
用户行为数据收集:实时收集用户在各个应用场景下的行为数据,如浏览记录、购买记录、评分等。
用户行为数据预处理:对收集到的用户行为数据进行清洗、去重、标准化等预处理操作。
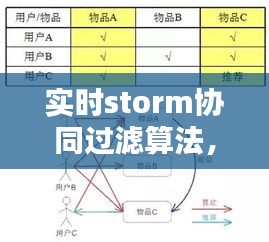
相似度计算:根据用户行为数据,计算用户之间的相似度,常用的相似度计算方法包括余弦相似度、皮尔逊相关系数等。
推荐生成:根据相似度计算结果,为用户生成推荐列表,推荐列表中的项目通常是用户相似用户喜欢的项目。
实时更新:实时监测用户行为数据的变化,动态调整推荐结果。
实时Storm协同过滤算法的实现方法
实时Storm协同过滤算法的实现主要依赖于Apache Storm这一实时大数据处理框架。以下是实现该算法的几个关键步骤:

搭建Storm集群:首先需要搭建一个Apache Storm集群,以便进行实时数据处理。
数据源接入:将用户行为数据源接入到Storm集群中,如数据库、消息队列等。
数据预处理:在Storm中编写数据预处理组件,对用户行为数据进行清洗、去重、标准化等操作。
相似度计算:编写相似度计算组件,根据用户行为数据计算用户之间的相似度。
推荐生成:编写推荐生成组件,根据相似度计算结果生成推荐列表。
结果输出:将推荐结果输出到目标系统,如Web服务器、移动应用等。
实时Storm协同过滤算法的优势
实时Storm协同过滤算法具有以下优势:
实时性:算法能够实时处理用户行为数据,快速生成推荐结果,满足用户对实时推荐的需求。
可扩展性:Apache Storm框架具有良好的可扩展性,能够适应大规模数据处理的场景。
高并发处理能力:Storm能够实现高并发处理,保证算法在大量用户行为数据下的性能。
容错性:Storm具有强大的容错机制,能够在节点故障的情况下保证数据处理任务的正常运行。
实际应用案例
实时Storm协同过滤算法在实际应用中取得了显著的效果。以下是一些典型的应用案例:
电子商务:实时推荐用户可能感兴趣的商品,提高用户购买转化率。
社交媒体:为用户推荐可能感兴趣的朋友、内容等,增强用户粘性。
在线教育:根据用户学习行为,推荐相关课程和资料,提高学习效果。
视频网站:为用户推荐相似的视频内容,提高用户观看时长。
总结
实时Storm协同过滤算法作为一种高效的实时推荐算法,在多个领域都得到了广泛应用。随着大数据技术的不断发展,实时Storm协同过滤算法有望在更多场景中发挥重要作用。本文对实时Storm协同过滤算法的原理、实现方法及其优势进行了详细阐述,为相关领域的研究和应用提供了参考。





 桂ICP备18009795号-1
桂ICP备18009795号-1